Visualizing Weights distill.pub 1h We present techniques for visualizing, contextualizing, and understanding neural network weights.
Machine Learning for Computer Architecture feedproxy.google.com 7h Posted by Amir Yazdanbakhsh, Research Scientist, Google Research One of the key contributors to recent machine learning (ML) advancements...
Using genetic algorithms on AWS for optimization problems aws.amazon.com 8h Machine learning (ML)-based solutions are capable of solving complex problems, from voice recognition to finding and identifying faces in video clips or photographs. Usually, these solutions use large amounts of training data, which results in a model that processes input data and produces numeric output that can be interpreted as a word, face, or classification […]
Creating a BankingBot on Amazon Lex V2 Console with support for English and Spanish aws.amazon.com 1d Amazon Lex is a service for building conversational interfaces into any application. The new Amazon Lex V2 Console and APIs make it easier to build, deploy, and manage bots. In this post, you will learn about about the 3 main benefits of Amazon Lex V2 Console and API, basic bot building concepts, and how to […]
Using Amazon Translate to provide language support to Amazon Kendra aws.amazon.com 1d Amazon Kendra is a highly accurate and easy-to-use intelligent search service powered by machine learning (ML). Amazon Kendra supports English. This post provides a set of techniques to provide non-English language support when using Amazon Kendra. We demonstrate these techniques within the context of a question-answer chatbot use case (Q&A bot) where a user can […]
Using the AWS DeepRacer new Soft Actor Critic algorithm with continuous action spaces aws.amazon.com 1d AWS DeepRacer is the fastest way to get started with machine learning (ML). You can train reinforcement learning (RL) models by using a 1/18th scale autonomous vehicle in a cloud-based virtual simulator and compete for prizes and glory in the global AWS DeepRacer League. We’re excited to bring you two new features available on the […]
Scheduling work meetings in Slack with Amazon Lex aws.amazon.com 1d Imagine being able to schedule a meeting or get notified about updates in your code repositories without leaving your preferred messaging platform. This could save you time and increase productivity. With the advent of chatbots, these mundane tasks are now easier than ever. Amazon Lex, a service for building chatbots, offers native integration with popular […]
Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning feedproxy.google.com 1d Posted by Mohammad Babaeizadeh, Research Engineer and Dumitru Erhan, Research Scientist, Google Research Model-free reinforcement learnin...
Brian Christian Talks the Alignment Problem blogs.nvidia.com 1d Brian Christian has just released The Alignment Problem, which examines what happens when AI models don’t do what they’re intended to do.
Automating complex deep learning model training using Amazon SageMaker Debugger and AWS Step Functions aws.amazon.com 2d Amazon SageMaker Debugger can monitor ML model parameters, metrics, and computation resources as the model optimization is in progress. You can use it to identify issues during training, gain insights, and take actions like stopping the training or sending notifications through built-in or custom actions. Debugger is particularly useful in training challenging deep learning model […]
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
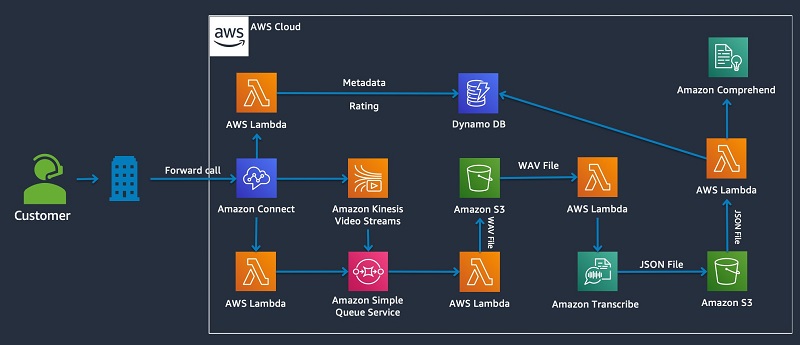
Setting up an IVR to collect customer feedback via phone using Amazon Connect and AWS AI Services aws.amazon.com 2d As many companies place their focus on customer centricity, customer feedback becomes a top priority. However, as new laws are formed, for instance GDPR in Europe, collecting feedback from customers can become increasingly difficult. One means of collecting this feedback is via phone. When a customer calls an agency or call center, feedback may be […]
Curve Circuits distill.pub 3d Reverse engineering the curve detection algorithm from InceptionV1 and reimplementing it from scratch.
This month in AWS Machine Learning: January edition aws.amazon.com 3d Hello and welcome to our first “This month in AWS Machine Learning” of 2021! Every day there is something new going on in the world of AWS Machine Learning—from launches to new to use cases to interactive trainings. We’re packaging some of the not-to-miss information from the ML Blog and beyond for easy perusing each […]
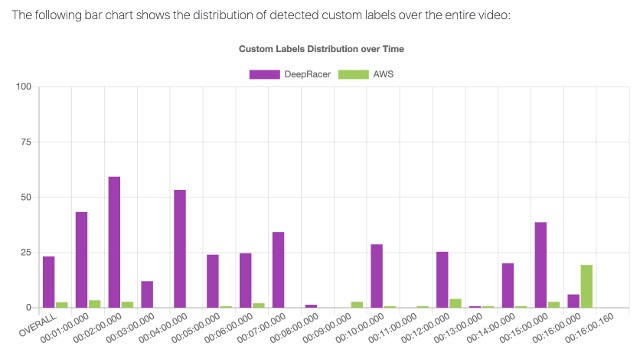
Get ready to roll! AWS DeepRacer pre-season racing is now open aws.amazon.com 3d AWS DeepRacer allows you to get hands on with machine learning (ML) through a fully autonomous 1/18th scale race car driven by reinforcement learning, a 3D racing simulator on the AWS DeepRacer console, a global racing league, and hundreds of customer-initiated community races. Pre-season qualifying underway We’re excited to announce that racing action is right […]
Import AI 234: Pre-training with fractals; compute&countries; GANS for good jack-clark.net 3d Where we’re going we don’t need data – we’ll pre-train on FRACTALS!!!!…This research technique is straight out of a Baudrillard notebook…In Simulacra and Simulation by French philosopher Jean Baudrillard, he argues that human society has become reliant on simulations of reality, with us trafficking in abstractions – international finance, televised wars – that feel in some way more real than...
#157 - Natalya Bailey: Rocket Engines and Electric Spacecraft Propulsion lexfridman.com 3d Natalya Bailey is a rocket propulsion engineer from MIT and now CTO of Accion Systems. Please support this podcast by checking out our sponsors: – Munk Pack: and use code LEX to get 20% off – Four Sigmatic: and use code LexPod to get up to 60% off – Blinkist: and use code LEX to get 25%...
Introducing spaCy v3.0 · Explosion explosion.ai 3d spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem....
On decoupling medium.com 4d What are the pros (and cons) of decoupling systems and organizations? When and how should you decouple? Is it worth it?
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
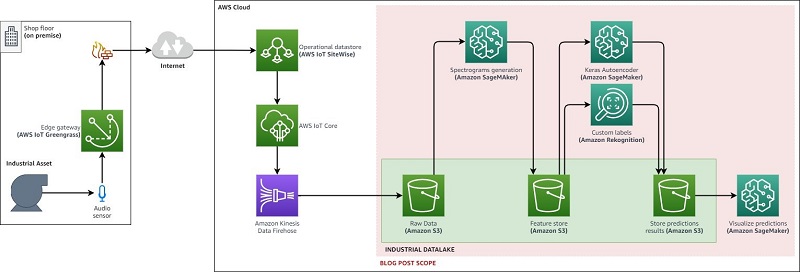
Performing anomaly detection on industrial equipment using audio signals aws.amazon.com 6d Industrial companies have been collecting a massive amount of time-series data about operating processes, manufacturing production lines, and industrial equipment. You might store years of data in historian systems or in your factory information system at large. Whether you’re looking to prevent equipment breakdown that would stop a production line, avoid catastrophic failures in a […]
Learning to Reason Over Tables from Less Data feedproxy.google.com 6d Posted by Julian Eisenschlos AI Resident, Google Research, Zürich The task of recognizing textual entailment , also known as natural lan...
Forecasting AWS spend using the AWS Cost and Usage Reports, AWS Glue DataBrew, and Amazon Forecast aws.amazon.com 7d AWS Cost Explorer enables you to view and analyze your AWS Cost and Usage Reports (AWS CUR). You can also predict your overall cost associated with AWS services in the future by creating a forecast of AWS Cost Explorer, but you can’t view historical data beyond 12 months. Moreover, running custom machine learning (ML) models […]
Managing your machine learning lifecycle with MLflow and Amazon SageMaker aws.amazon.com 7d With the rapid adoption of machine learning (ML) and MLOps, enterprises want to increase the velocity of ML projects from experimentation to production. During the initial phase of an ML project, data scientists collaborate and share experiment results in order to find a solution to a business need. During the operational phase, you also need […]
Improving Mobile App Accessibility with Icon Detection feedproxy.google.com 7d Posted by Gilles Baechler and Srinivas Sunkara, Software Engineers, Google Research Voice Access enables users to control their Android ...
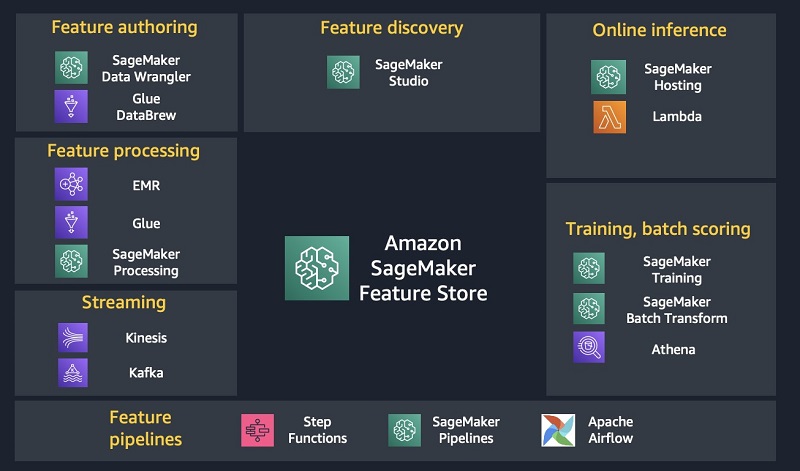
Understanding the key capabilities of Amazon SageMaker Feature Store aws.amazon.com 7d One of the challenging parts of machine learning (ML) is feature engineering, the process of transforming data to create features for ML. Features are processed data signals used for training ML models and for deployed models to make accurate predictions. Data scientists and ML engineers can spend up to 60-70% of their time on feature […]
Saving time with personalized videos using AWS machine learning aws.amazon.com 7d CLIPr aspires to help save 1 billion hours of people’s time. We organize video into a first-class, searchable data source that unlocks the content most relevant to your interests using AWS machine learning (ML) services. CLIPr simplifies the extraction of information in videos, saving you hours by eliminating the need to skim through them manually […]
Deepset achieves a 3.9x speedup and 12.8x cost reduction for training NLP models by working with AWS and NVIDIA aws.amazon.com 8d This is a guest post from deepset (creators of the open source frameworks FARM and Haystack), and was contributed to by authors from NVIDIA and AWS. At deepset, we’re building the next-level search engine for business documents. Our core product, Haystack, is an open-source framework that enables developers to utilize the latest NLP models for […]
Addressing Range Anxiety with Smart Electric Vehicle Routing feedproxy.google.com 8d Posted by Kostas Kollias and Sreenivas Gollapudi, Research Scientists, Geo Algorithms Team, Google Research Mapping algorithms used for n...
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
High/Low frequency detectors distill.pub 8d A family of early-vision filters reacting to contrasts between spatial gratings of different frequency
How to deliver natural conversational experiences using Amazon Lex Streaming APIs aws.amazon.com 9d Natural conversations often include pauses and interruptions. During customer service calls, a caller may ask to pause the conversation or hold the line while they look up the necessary information before continuing to answer a question. For example, callers often need time to retrieve credit card details when making bill payments. Interruptions are also common. […]
Stabilizing Live Speech Translation in Google Translate feedproxy.google.com 9d Posted by Naveen Arivazhagan, Senior Software Engineer and Colin Cherry, Staff Research Scientist, Google Research The transcription fea...
Certifiably Fast: Top OEMs Debut World’s First NVIDIA-Certified Systems Built to Crush AI Workloads blogs.nvidia.com 9d First of its kind program marks the only accelerated servers to get road tested for the journey to machine learning and analytics.
Design progresses for MIT Schwarzman College of Computing building on Vassar Street news.mit.edu 9d The MIT Schwarzman College of Computing is planning a new building on Vassar Street in Cambridge, envisioned to create a hub for computing research and education at MIT. Designed alongside Skidmore, Owings & Merrill, the building will include spaces that will be inviting to members of the campus community and the public.
Learning with — and about — AI technology news.mit.edu 10d MIT Media Lab Personal Robots group head Cynthia Breazeal joined MIT Education Arcade Director Eric Klopfer for a conversation about AI's role in K-12 education as part of a new webinar series from MIT Open Learning.
Model serving in Java with AWS Elastic Beanstalk made easy with Deep Java Library aws.amazon.com 10d Deploying your machine learning (ML) models to run on a REST endpoint has never been easier. Using AWS Elastic Beanstalk and Amazon Elastic Compute Cloud (Amazon EC2) to host your endpoint and Deep Java Library (DJL) to load your deep learning models for inference makes the model deployment process extremely easy to set up. Setting […]
Building your own brand detection and visibility using Amazon SageMaker Ground Truth and Amazon Rekognition Custom Labels aws.amazon.com 10d According to Gartner, 58% of marketing leaders believe brand is a critical driver of buyer behavior for prospects, and 65% believe it’s a critical driver of buyer behavior for existing customers. Companies spend huge amounts of money on advertisement to raise brand visibility and awareness. In fact, as per Gartner, CMO spends over 21% of […]
Scaling Kubernetes to 7,500 Nodes openai.com 10d We've scaled Kubernetes clusters to 7,500 nodes, producing a scalable infrastructure for large models like GPT-3, CLIP, and DALL·E, but also for rapid small-scale iterative research such as Scaling Laws for Neural Language Models. Scaling a single Kubernetes cluster to this size is rarely done and requires some
Model serving made easier with Deep Java Library and AWS Lambda aws.amazon.com 10d Developing and deploying a deep learning model involves many steps: gathering and cleansing data, designing the model, fine-tuning model parameters, evaluating the results, and going through it again until a desirable result is achieved. Then comes the final step: deploying the model. AWS Lambda is one of the most cost effective service that lets you run code without […]
Import AI 233: AI needs AI designers; estimating COVID risk with AI; the dreams of an old computer programmer. jack-clark.net 10d Facebook trains a COVID-risk-estimating X-ray image analysis system:…Collaboration with NYU yields a COVID-spotting AI model…Facebook has worked with NYU to analyze chest X-rays from people with COVID and has created an AI system that can roughly estimate risks for different people. One of the things this work sheds light on is the different amounts of data we need for training...
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
Multi-account model deployment with Amazon SageMaker Pipelines aws.amazon.com 13d Amazon SageMaker Pipelines is the first purpose-built CI/CD service for machine learning (ML). It helps you build, automate, manage, and scale end-to-end ML workflows and apply DevOps best practices of CI/CD to ML (also known as MLOps). Creating multiple accounts to organize all the resources of your organization is a good DevOps practice. A multi-account […]
Improving Indian Language Transliterations in Google Maps feedproxy.google.com 13d Posted by Cibu Johny, Software Engineer, Google Research and Saumya Dalal, Product Manager, Google Geo Nearly 75% of India’s population —...
Amazon Lex Introduces an Enhanced Console Experience and New V2 APIs aws.amazon.com 14d Today, the Amazon Lex team has released a new console experience that makes it easier to build, deploy, and manage conversational experiences. Along with the new console, we have also introduced new V2 APIs, including continuous streaming capability. These improvements allow you to reach new audiences, have more natural conversations, and develop and iterate faster. […]
Fengdi Guo awarded first place in LTTP Data Analysis Student Contest news.mit.edu 14d In a prize-winning paper, Fengdi Guo, a PhD candidate at the MIT Concrete Sustainability Hub, helps clarify the layered relationship between traffic weight and pavement deterioration.
RxR: A Multilingual Benchmark for Navigation Instruction Following feedproxy.google.com 14d Posted by Alexander Ku, Software Engineer and Peter Anderson, Research Scientist, Google Research A core challenge in machine learning (M...
Otter.ai Brings Live Captions to a Meeting Near You blogs.nvidia.com 14d Sam Liang is the CEO and co-founder of , which uses AI to produce speech-to-text transcriptions in real time.
Redacting PII from application log output with Amazon Comprehend aws.amazon.com 15d Amazon Comprehend is a natural language processing (NLP) service that uses machine learning (ML) to find insights and relationships in text. The service can extract people, places, sentiments, and topics in unstructured data. You can now use Amazon Comprehend ML capabilities to detect and redact personally identifiable information (PII) in application logs, customer emails, support […]