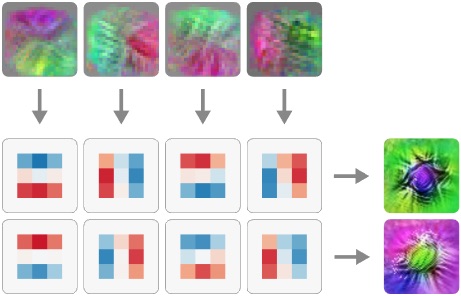
Visualizing Weights distill.pub 1h We present techniques for visualizing, contextualizing, and understanding neural network weights.
Machine Learning for Computer Architecture feedproxy.google.com 7h Posted by Amir Yazdanbakhsh, Research Scientist, Google Research One of the key contributors to recent machine learning (ML) advancements...
Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning feedproxy.google.com 1d Posted by Mohammad Babaeizadeh, Research Engineer and Dumitru Erhan, Research Scientist, Google Research Model-free reinforcement learnin...
Curve Circuits distill.pub 3d Reverse engineering the curve detection algorithm from InceptionV1 and reimplementing it from scratch.
#157 - Natalya Bailey: Rocket Engines and Electric Spacecraft Propulsion lexfridman.com 3d Natalya Bailey is a rocket propulsion engineer from MIT and now CTO of Accion Systems. Please support this podcast by checking out our sponsors: – Munk Pack: and use code LEX to get 20% off – Four Sigmatic: and use code LexPod to get up to 60% off – Blinkist: and use code LEX to get 25%...
Learning to Reason Over Tables from Less Data feedproxy.google.com 6d Posted by Julian Eisenschlos AI Resident, Google Research, Zürich The task of recognizing textual entailment , also known as natural lan...
Improving Mobile App Accessibility with Icon Detection feedproxy.google.com 7d Posted by Gilles Baechler and Srinivas Sunkara, Software Engineers, Google Research Voice Access enables users to control their Android ...
Addressing Range Anxiety with Smart Electric Vehicle Routing feedproxy.google.com 8d Posted by Kostas Kollias and Sreenivas Gollapudi, Research Scientists, Geo Algorithms Team, Google Research Mapping algorithms used for n...
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
High/Low frequency detectors distill.pub 8d A family of early-vision filters reacting to contrasts between spatial gratings of different frequency
Stabilizing Live Speech Translation in Google Translate feedproxy.google.com 9d Posted by Naveen Arivazhagan, Senior Software Engineer and Colin Cherry, Staff Research Scientist, Google Research The transcription fea...
Scaling Kubernetes to 7,500 Nodes openai.com 10d We've scaled Kubernetes clusters to 7,500 nodes, producing a scalable infrastructure for large models like GPT-3, CLIP, and DALL·E, but also for rapid small-scale iterative research such as Scaling Laws for Neural Language Models. Scaling a single Kubernetes cluster to this size is rarely done and requires some
Improving Indian Language Transliterations in Google Maps feedproxy.google.com 13d Posted by Cibu Johny, Software Engineer, Google Research and Saumya Dalal, Product Manager, Google Geo Nearly 75% of India’s population —...
RxR: A Multilingual Benchmark for Navigation Instruction Following feedproxy.google.com 14d Posted by Alexander Ku, Software Engineer and Peter Anderson, Research Scientist, Google Research A core challenge in machine learning (M...
ToTTo: A Controlled Table-to-Text Generation Dataset feedproxy.google.com 20d Posted by Ankur Parikh and Xuezhi Wang, Research Scientists, Google Research In the last few years, research in natural language generati...
Recognizing Pose Similarity in Images and Videos feedproxy.google.com 21d Posted by Jennifer J. Sun, Student Researcher and Ting Liu, Senior Software Engineer, Google Research Everyday actions, such as jogging, ...
Google Research: Looking Back at 2020, and Forward to 2021 feedproxy.google.com 23d Posted by Jeff Dean, Senior Fellow and SVP of Google Research and Health, on behalf of the entire Google Research community When I joined...
Hybrid chips can run AI on battery-powered devices news.stanford.edu 24d In traditional electronics, separate chips process and store data, wasting energy as they toss data back and forth over what engineers call a “memory wall.” New algorithms combine several energy-efficient hybrid chips to create the illusion of one mega–AI chip.
DALL·E: Creating Images from Text openai.com on 5 January We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
CLIP: Connecting Text and Images openai.com on 5 January We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision.
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
Organizational Update from OpenAI openai.com on 29 December It’s been a year of dramatic change and growth at OpenAI. In May, we introduced GPT-3—the most powerful language model to date—and soon afterward launched our first commercial product, an API to safely access artificial intelligence models using simple, natural-language prompts. We’re proud of these and
#149 - Diana Walsh Pasulka: Aliens, Technology, Religion, and the Nature of Belief lexfridman.com on 28 December Diana Walsh Pasulka is a professor of philosophy and religion at UNCW and author of American Cosmic: UFOs, Religion, and Technology. Please support this podcast by checking out our sponsors: – LMNT: to get free shipping – Grammarly: to get 20% off premium – Business Wars: – Cash App: and use code LexPodcast to get $10...
#148 - Charles Isbell and Michael Littman: Machine Learning and Education lexfridman.com on 26 December Charles Isbell is the Dean of the College of Computing at Georgia Tech. Michael Littman is a computer scientist at Brown University. Please support this podcast by checking out our sponsors: – Athletic Greens: and use code LEX to get 1 month of fish oil – Eight Sleep: and use code LEX to get special savings – MasterClass:...
Better Language Models and Their Implications openai.com on 22 December We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks, and performs rudimentary reading comprehension, machine translation, question answering, and summarization.
End-to-End, Transferable Deep RL for Graph Optimization feedproxy.google.com on 17 December Posted by Yanqi Zhou and Sudip Roy, Research Scientists, Google Research An increasing number of applications are driven by large and co...
My heartfelt apology animakumar.wpcomstaging.com on 17 December I want to wholeheartedly apologize to everyone hurt by my words. I want to assure you that I bear no animosity. I want to be part of an inclusive community where all voices are heard. I am so…
My departure from Twitter animakumar.wpcomstaging.com on 16 December Many of you are very concerned about why my Twitter account is no longer active. I have voluntarily decided to de-activate my account in the interest of my safety and to reduce anxiety for my loved…
Privacy Considerations in Large Language Models feedproxy.google.com on 15 December Posted by Nicholas Carlini, Research Scientist, Google Research Machine learning-based language models trained to predict the next word i...
Pain and Machine Learning blog.shakirm.com on 12 December Was so excited to get this opportunity to talk about pain and learning at the NeurIPS2020 Workshop on Biological and Artificial RL. This is the text of the talk.:film_frames:Watch the video h…
Portrait Light: Enhancing Portrait Lighting with Machine Learning feedproxy.google.com on 11 December Posted by Yun-Ta Tsai 1 and Rohit Pandey, Software Engineers, Google Research Professional portrait photographers are able to create com...
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
Through the Eyes of Birds and Frogs: Writing and Surveys in Machine Learning Research blog.shakirm.com on 11 December Savoured the opportunity to talk about writing surveys and reviews at the NeurIPS2020 Workshop on ML Retrospectives, Surveys & Meta-Analyses (ML-RSA) This is the text of the talk. :film_frames:Watc…
MediaPipe Holistic — Simultaneous Face, Hand and Pose Prediction, on Device feedproxy.google.com on 10 December Posted by Ivan Grishchenko and Valentin Bazarevsky, Research Engineers, Google Research Real-time, simultaneous perception of human pose...
A Model-Based Approach Towards Identifying the Brain’s Learning Algorithms ai.stanford.edu on 9 December Introduction
Naturally Occurring Equivariance in Neural Networks distill.pub on 8 December Neural networks naturally learn many transformed copies of the same feature, connected by symmetric weights.
Studying trust in autonomous products news.stanford.edu on 8 December Stanford engineers investigated how people’s moods might affect their trust of autonomous products, such as smart speakers. They uncovered a complicated relationship.
iGibson: A Simulation Environment to Train AI Agents in Large Realistic Scenes ai.stanford.edu on 8 December Why simulation for AI?
Offline Reinforcement Learning: How Conservative Algorithms Can Enable New Applications bair.berkeley.edu on 7 December The BAIR Blog
Google at NeurIPS 2020 feedproxy.google.com on 7 December Posted by Jaqui Herman and Cat Armato, Program Managers This week marks the beginning of the 34 th annual Conference on Neural Informatio...
Stanford AI Lab Papers and Talks at NeurIPS 2020 ai.stanford.edu on 7 December The official Stanford AI Lab blog
Using AutoML for Time Series Forecasting feedproxy.google.com on 4 December Posted by Chen Liang and Yifeng Lu, Software Engineers, Google Research, Brain Team Time series forecasting is an important research are...
Transformers for Image Recognition at Scale feedproxy.google.com on 3 December Posted by Neil Houlsby and Dirk Weissenborn, Research Scientists, Google Research While convolutional neural networks (CNNs) have been u...
Your ML ad here you.com soon Call for papers? New API? Kaggle competition? Open position? Now you can advertise opportunities relevant to machine learning here. Ping [email protected]
Can implicit regularization in deep learning be explained by norms? offconvex.github.io on 27 November Algorithms off the convex path.
Navigating Recorder Transcripts Easily, with Smart Scrolling feedproxy.google.com on 24 November Posted by Itay Inbar, Senior Software Engineer, Google Research Last year we launched Recorder , a new kind of recording app that made au...
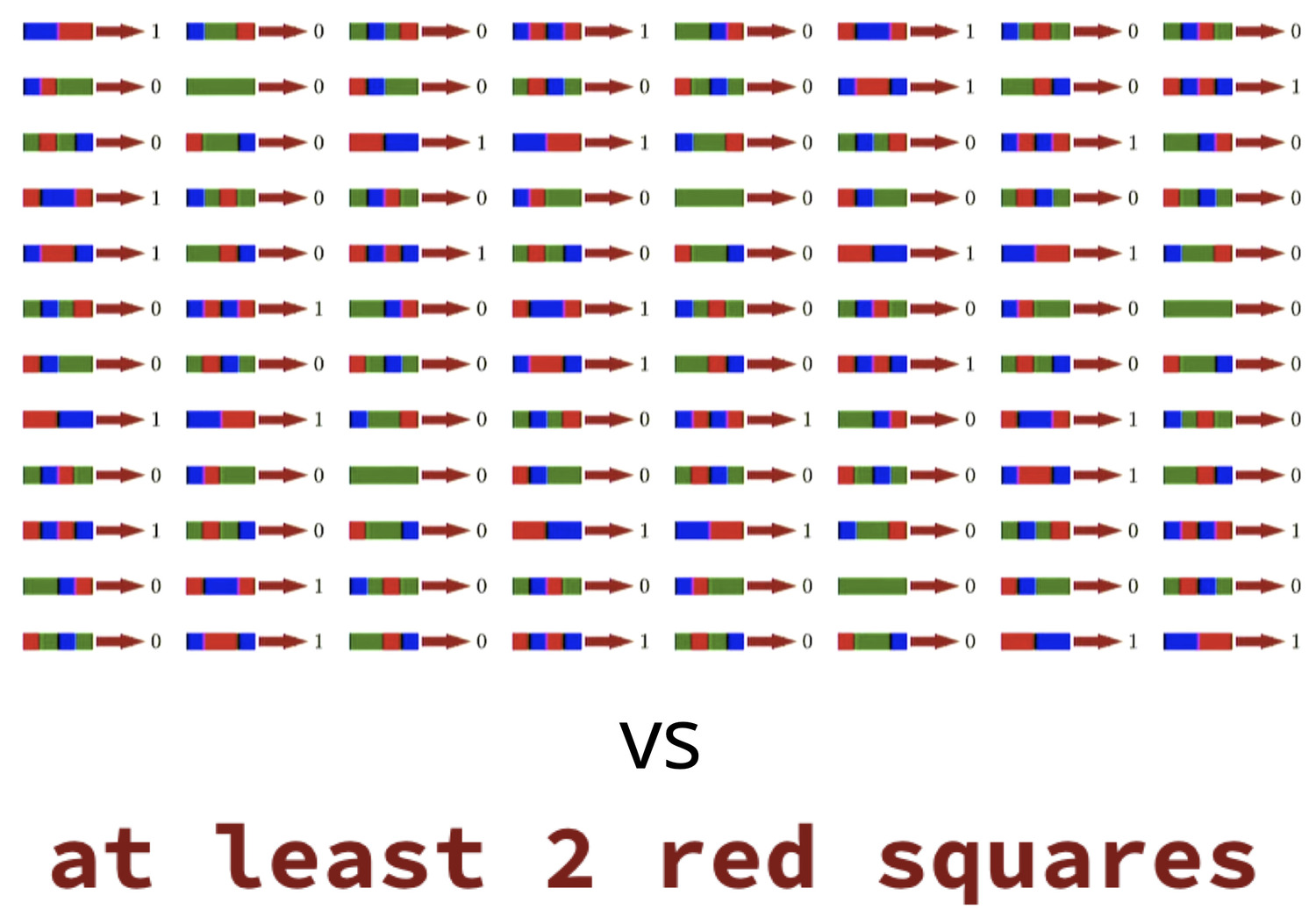
Learning from Language Explanations ai.stanford.edu on 23 November Imagine you’re a machine learning practitioner and you want to solve some classification problem, like classifying groups of colored squares as being either 1s or 0s. Here’s what you would typically do: collect a large dataset of examples, label the data, and train a classifier:
The Language Interpretability Tool (LIT): Interactive Exploration and Analysis of NLP Models feedproxy.google.com on 20 November Posted by James Wexler, Software Developer and Ian Tenney, Software Engineer, Google Research As natural language processing (NLP) models...
#140 - Lisa Feldman Barrett: Love, Evolution, and the Human Brain lexfridman.com on 20 November Lisa Feldman Barrett is a neuroscientist, psychologist, and author. Please support this podcast by checking out our sponsors: – Athletic Greens: and use code LEX to get 1 month of fish oil – Eight Sleep: and use code LEX to get $200 off – MasterClass: to get 15% off annual sub – BetterHelp: to get 10%...
Haptics with Input: Using Linear Resonant Actuators for Sensing feedproxy.google.com on 18 November Posted by Artem Dementyev, Hardware Engineer, Google Research As wearables and handheld devices decrease in size, haptics become an incr...